Clean architecture
In this article I will discuss about a set of patterns, practices, and principles in order to create a better architecture, as an alternative to the traditional three-layered database-centric architecture we have been using for decades. Here is an illustration of the traditional 3 Layer Architecture:
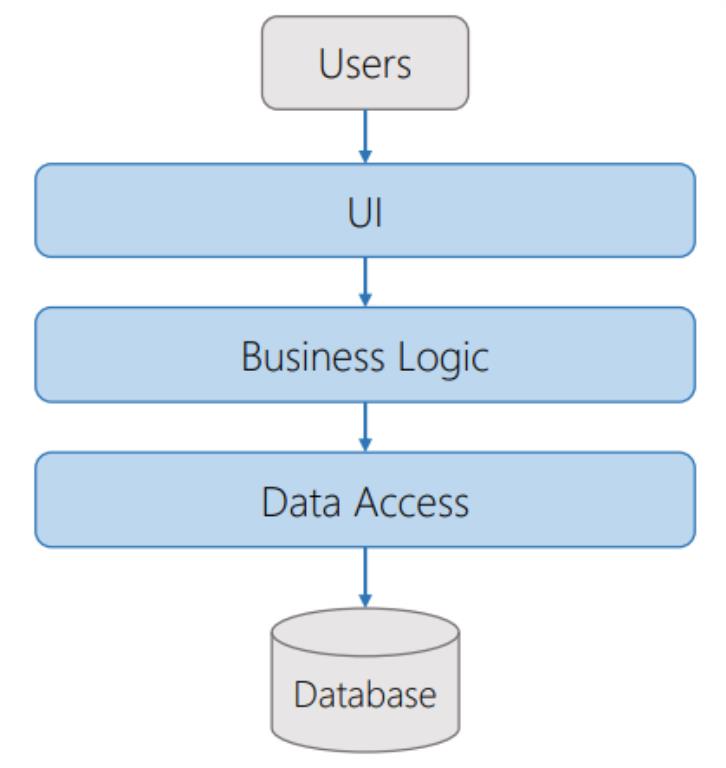
Compared to this architecture, I will present some alternatives for better extensibility, maintainability and usability.
This new approach will allow you to evolve the architecture as the needs of the system changes over time.
We are focusing here on the architecture of Enterprise applications, meaning applications to solve business problems. We are focusing on an alternative of creating such applications, compared to the traditional three layered database centric architecture. In contrast to the classical waterfall software development process, the agile software development process helps building the architecture in an iterative and evolutionary manner.
What is software architecture?
Software architecture can be seen as a higher level than the code we write. It has to do with the structure of software, or how things are organized. It includes Layers, which are vertical partitions of the system.
It typically also involves components, which are horizontal partitions within each of these layers. Then, it involves the relationship between the mentioned parts, meaning how they are wired together.
Layers of abstraction:
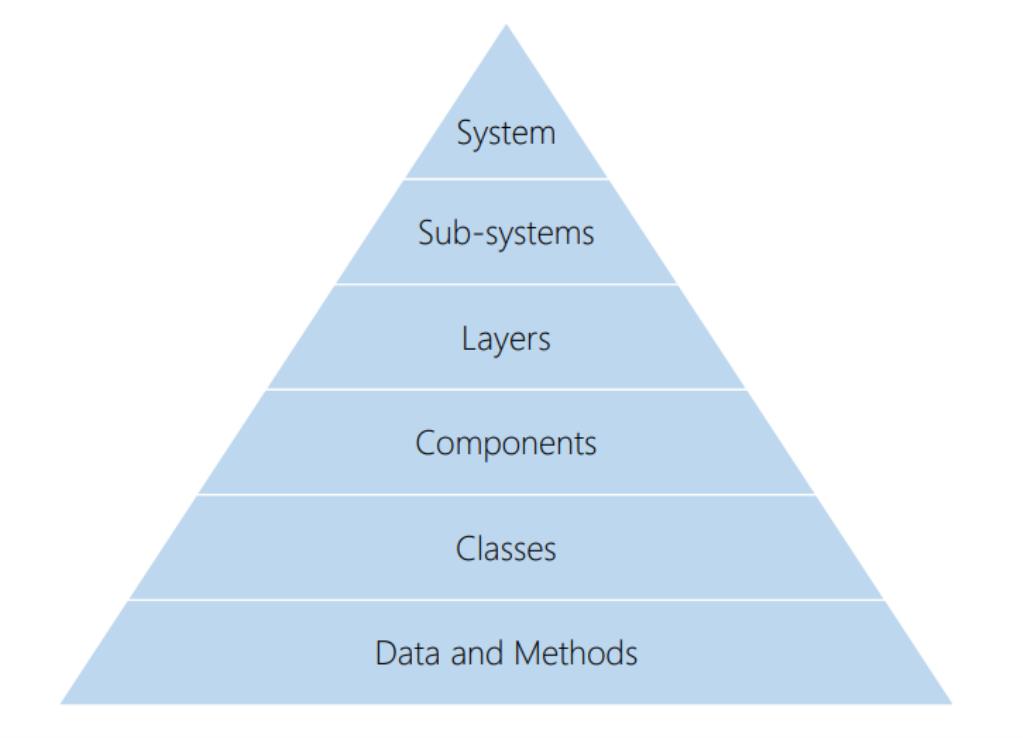
Good Architecture
-Simple
-Understandable
-Flexible
-Emergent
-Testable
-Maintainable
Software architecture should be designed for the inhabitants of the architecture, not for the architect or for the machine. The inhabitants are considered the people which will be using the architecture during the life of the projects: the user of the systems, the developers building it, and the developers maintaining it.
By not designing for the architect, means that the architect should put his desires, preferences and wishes, and consider only what is best for the inhabitants of the system.
By not designing for the machine, means that we should optimize the architecture first for the inhabitants, and only optimize for the machine when the cost of performance for the machine when the cost of performance issues to the users outweighs the benefit of a clean design of the developers, which
are also inhabitants of the architecture. It's all about avoiding premature optimization, the primary focus is to design the architecture for the inhabitants of the system.
The philosophy is to focus on what is essential to the software architecture versus what is just an implementation detail.
Agile Iterative approach helps minimizing risk for the business, by early detecting Problems. Being able to react on this Problems early will help us to change the architecture in time.
Domain centric Architecture
Database- vs. Domain-centric Architecture
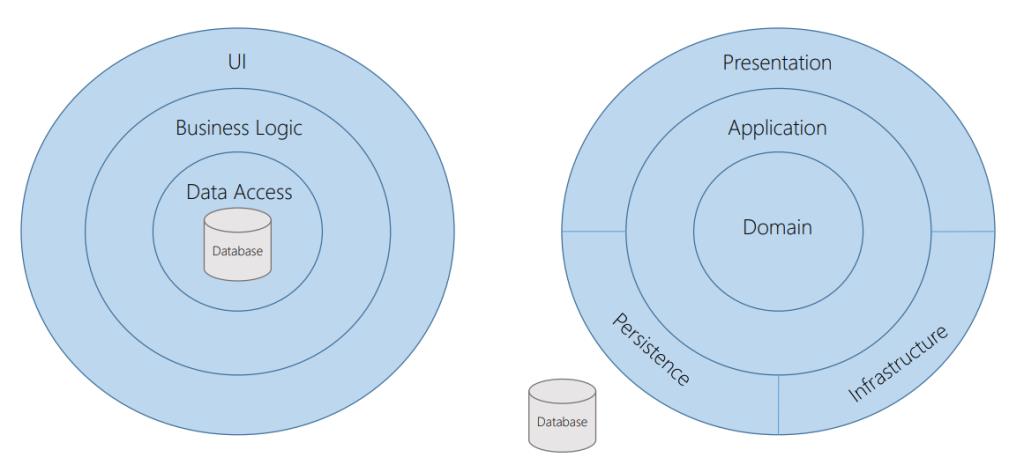
With Database-centric applications, the database is at the center of the application, and all dependencies point toward the database. With Domain centric applications, the domain and use cases are essential, and the presentation and persistence are only details.
With Domain centric architecture, the focus is put on the domain, which is essential to the inhabitants of the architecture, that is the users and developers of the applications.
Second, there is less coupling between domain logic and the implementation details, for example the presentation, database and operating system.
Using a Domain centric architecture allows us to incorporate Domain Driven Design, which is a set of strategies for handling business domains with a high degree of complexity.
You can find an article on Domain Driven design under the following link:
http://www.pinte.ro/Blog/IT/DDD-Domain-Driven-Design-for-modelling-complex-business-applications/12
The domain model is an abstract representation of the business problem being solved. All of the classes properties and methods should correspond to the concepts that exist in the business world in the language of the business. There should be no details about persistence, infrastructure or presentation in the domain model.
Cons of domain driven architecture
1. First, change is difficult, most developers have been thought only the traditional three layer architecture.
2. Second, it requires more thought to implement domain-centric design. You need to differentiate between classes in the domain layer, and classes in the application layer.(rather than just putting everything in the business layer)
3. Third, it has a higher initial cost compared to the traditional 3 layer architecture.
Application Layer
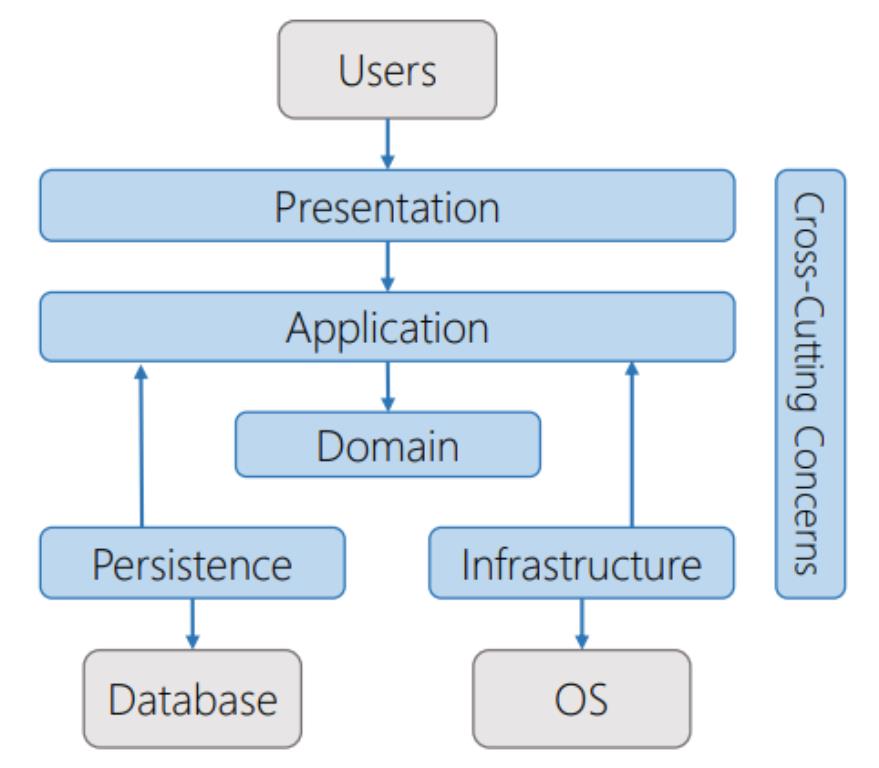
In this diagram we have different layers.
The Presentation layer provides the user an interface into the application. For example, in a ASP.NET MVC application, the controller is responsible of delegating work to the application layer, through an interface which is injected using an IoC container.
The application layer embeds the use cases of the application as executable code and abstractions.
The domain layer contains only the domain logic of the application.
The Infrastructure layer, composed of the persistence and Infrastructure components can be put separately into one or more projects.
The persistence layer provides an interface to the application layer to the database or other persistent storage.
The infrastructure layer provides an interface to the operating system and other third party components.
The cross cutting concerns layer contains aspects of the application that cross all the layers of the system.
There are more variations to this architecture, like multiple user interfaces, adding a web service layer or separate projects for external dependencies.
The application layer implements the use cases of the application, it knows about the domain layer(has a dependency), but has no knowledge about other layers directly. It just knows about the interfaces of the outer layers. With an IoC Framework it can get this dependencies injected at runtime.
Dependencies between layers
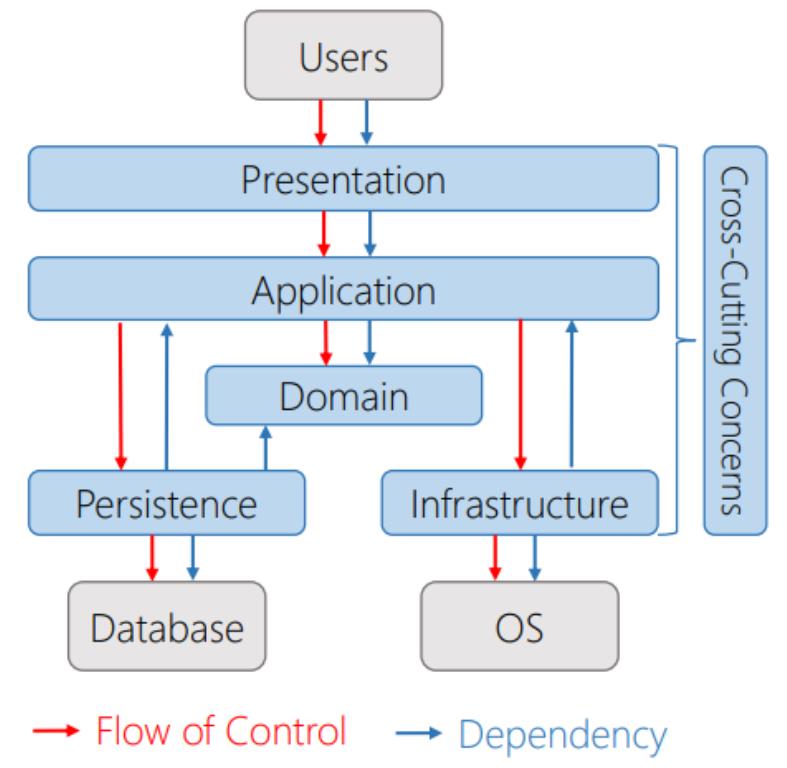
With dependencies inversion, the arrow between Persistence/Infrastructure and Application is reasonable, because the abstraction should not depend on details, but details should depend on abstractions. With this architecture, we can easily exchange the persistence layer of the application, without altering the abstractions that it depends upon.
Sometimes we need also an additional dependency from the persistence project directly to the domain project, when using an Object Relational Mapper(ORM) to map domain entities to tables in the database. Using an ORM is optional for clean architecture, but it can save a lot of time when used correctly.
The application layer embeds use cases as high level executable code, which delegates low level steps to other classes. This makes it easier to understand and easier to maintain. It uses the dependency inversion principle which allows us to defer implementation decisions until later, and evolve the architecture over time.
Cons of application layer
In general, there is an additional cost when adding an extra layer in general. It requires extra cost of thinking what belongs in the application layer or not. In the traditional architecture it was easier to put everything in the business logic layer.
CQRS
The Command-Query Separation principle states that we should maintain separation between commans and queries where possible. Commands are doing something, should not modify state, and should not return a value. A query does answer a question, should not modify state, and should return a value.
There are different type of CQRS Models, all of them are dealing with the separation of commands and queries. The simplest one is the single-database CQRS.
A counterexample to this pattern is a stack, when you get an item, through Pop. Calling Pop on a stack removes an item(command), and also returns the top item(query)
Single-database CQRS
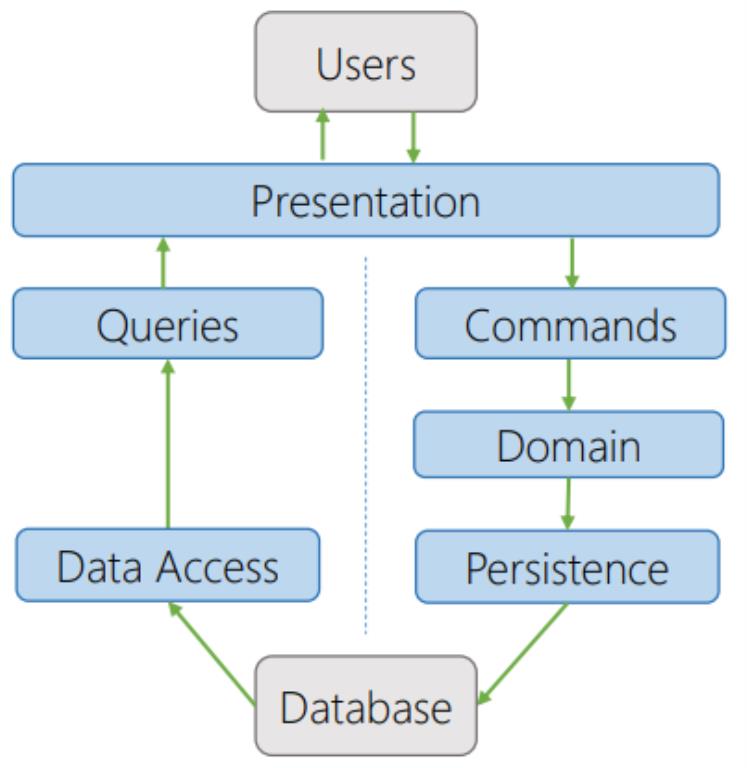
This type of CQRS has a single database that is either a normal relational Database or a NoSQL Database. Commands and queries are executed directly against a data access layer, for example using an ORM mapper like Entity Framework.
Two-databases CQRS
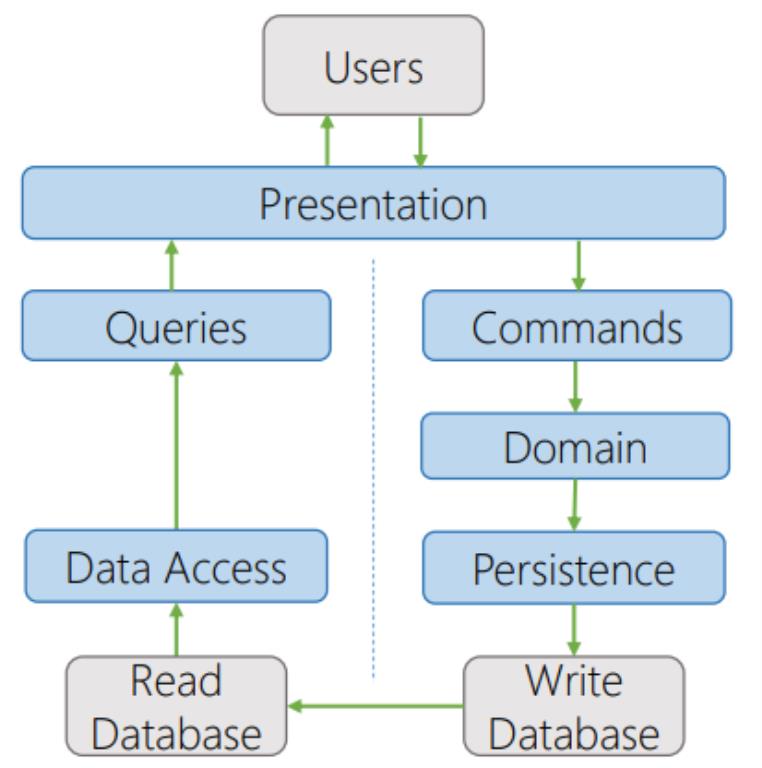
This type of CQRS has both a read database and a write database. The command stack has a database optimized for write operations, and the query stack has a database optimized for read operations. The two databases might be out of sync until the changes are propagated between the databases, but typically this goes very fast.
Event Sourcing CQRS
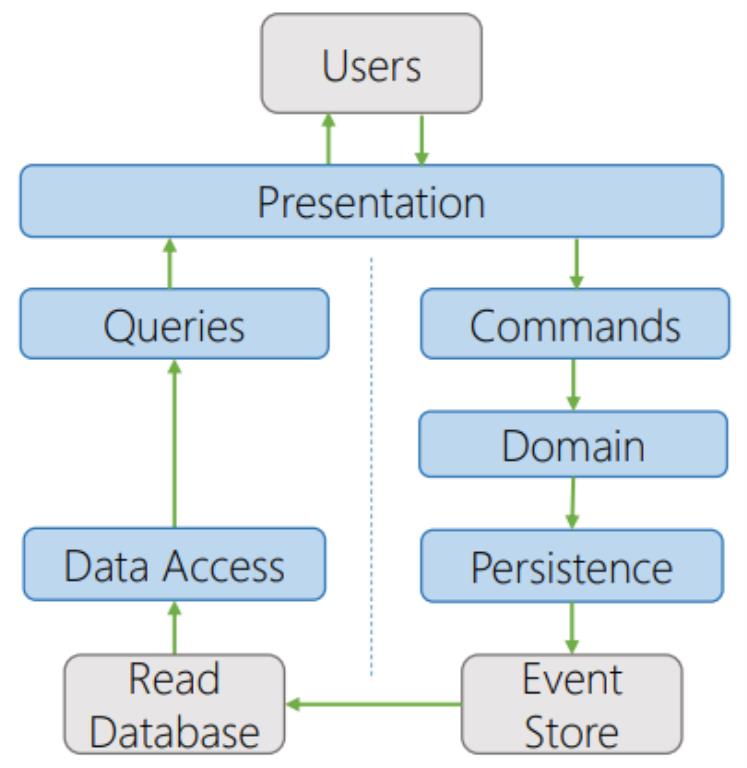
The main difference in this CQRS Architecture is that we do not store the current state of our entities in a normalized data store, instead, we store just the state modifications to the entities over time. The event store keeps a history of all events which happened to an entity, so that the current state can be reconstructed if needed. Finally, we push the current state of our entity out to the read database. The event store acts also as an audit trail for the entire system, and is useful if we want to reconstruct the state of an entity in any point in time.
Functional organization
We can use functional cohesion to organize Classes, Folders and namespaces of the system.
Compared to the categorical Architecture, the functional Architecture organizes related items together.
The following pictures shows the difference between a categorical architecture(like in a mvc project) and a functional organization, where related items are placed together based on an aggregate root.

There are pros and cons to each of this architectures, it depends on each project separately. We can use functional organization to have a better spatial locality, easier navigation. on the other hand, we may lose framework conventions, automatic scaffolding, and it might be harder to implement at first.
Microservices
Components are how we subdivide the layers of our architecture once it grows beyond a manageable size.
The data for each component stack is typically stored into a single database.
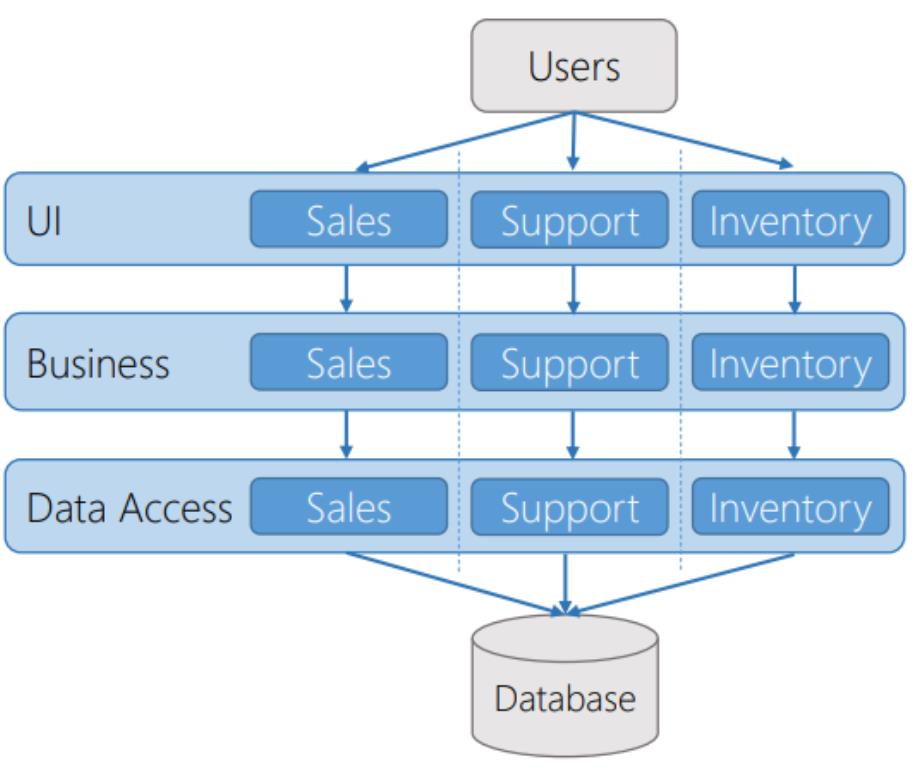
We can have this way entities which are used in different components, like in Sales and Support, and have nullable fields for properties which are not used in each use case. However, if the domain grows, it because harder to maintain and understand such entities.
If we try to use the same models in multiple contexts, things get more complicated. For example we mighht have validation rules, which are applicable in one context, but not in the other one. The solution is bounded contexts.
Bounded contexts
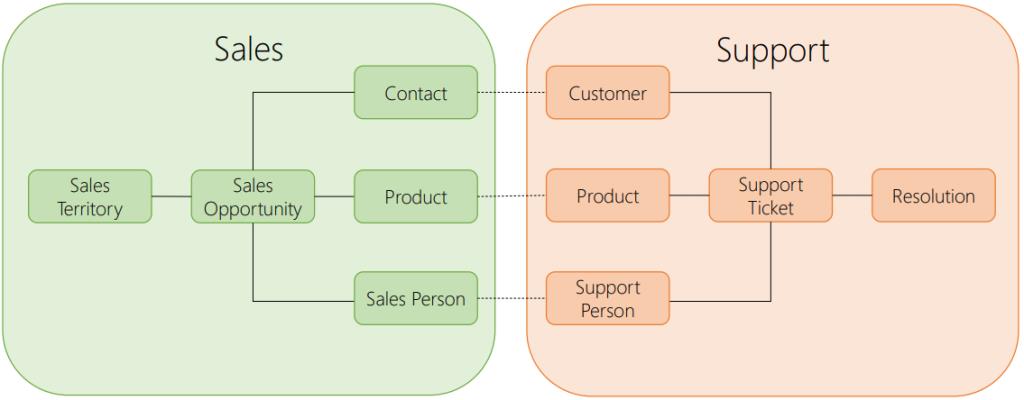
A bounded context is the recognition of a specific textual scope, within a specific model is valid. We communicate state transition of our cross boundary models from one domain to the other. We need to have clearly defined interfaces to communicate between this bounded contexts. This leads us to microservices.
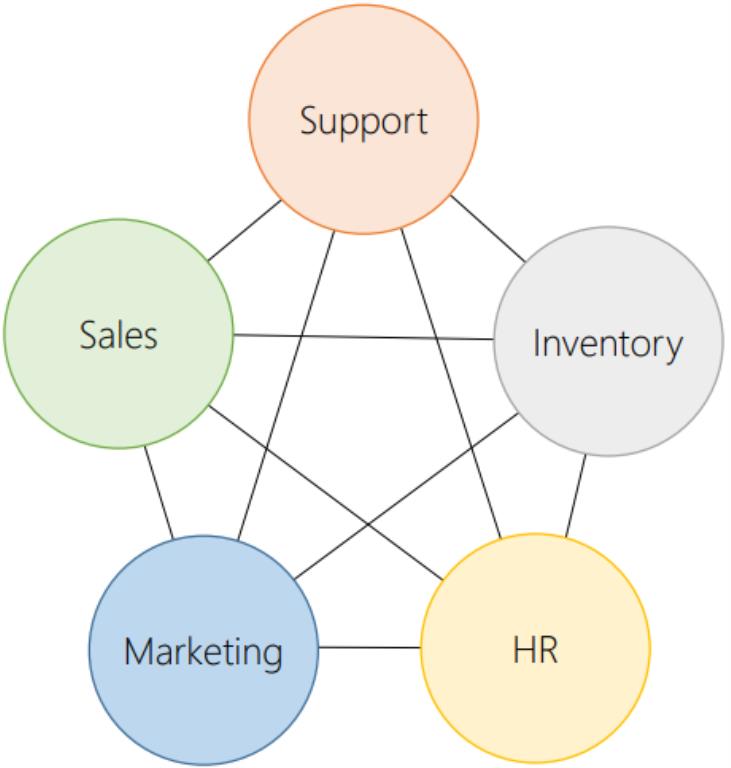
Microservices subdivide large monolithic applications, into microservices with clearly-defined interfaces. Different teams can work independently on one or more microservices. Each microservices can have different databases, different architecture, programming language, operating system, and can be deployed independently.
Microservices are similar to the concept of Service Oriented Architecture(SOA), however they don't prescribe the use of an enterprise service bus. Microservices should have a natural alignment to that of a bounded context. With bounded contexts, each team is focusing on a single domain of knowledge. They don't necessary need to know the details of any other microservice, just how to communicate with the interfaces of the other microservices. A microservice has a consistent data model, it does not need to be consistent with data from other microservices.
Microservices are valuable for agile software development teams, using agile practices to develop large business applications.
There is no clear definition of how big or small a microservice should be, one option is to create one microservice per aggregate root within each bounded context.
Speaking metaphorically, in contrast to the classical architectures of spaghetti and lasagna code, microservices can be seen as "ravioli" :)
For small systems, the cost of using microservices is initially higher, but it grows much more slower as the system gets bigger. Microservices have a flatter cost curve, provide higher cohesion/coupling in our codebase, and improve domain knowledge.
There is additional cost when developing distributed systems, you have to deal with network latency, load balancing and more. Experts recommend to start with a single application, and only break the application into microservices when it gets harder to deal with a monolitic application, instead of a microservices architecture.
This happens especially if you try to overlap multiple bounded contexts into the same monolithic application.
Testable Architecture
Clean architecture makes testing much more easier. Test driven development(TDD) helps building a clean architecture by first writing the tests first. By creating testable code, we are creating more maintainable code and we improve the design of our architecture.
Initially these tests fails but as we add more application code these tests pass. This helps us in many ways:
- We write application code based on the tests. This gives a test first environment for development and the generated application code turns out to be bug free.
- With each iteration we write tests and as a result with each iteration we get an automated regression pack. This turns out to be very helpful because with every iteration we can be sure that earlier features are working.
- These tests serve as documentation of application behavior and reference for future iterations.
Using Dependency injection, components can be tested easily by replacing non relevant external dependencies with mocks, that means using a mocking framework in order to generate fake objects.
With a testable architecture we eliminate fear, because once unit tests are in place, it's easier to change and refactor a codebase, because we detect errors early by the unit tests.
There is a higher initial cost of adopting TDD, but, in larger applications it pays off in the long term.
Behavior Driven Development
Behavior Driven testing(BDD) is an extension of TDD. Like in TDD in BDD also we write tests first and the add application code. The major difference that we get to see here are:
- Tests are written in plain descriptive English type grammar
- Tests are explained as behavior of application and are more user focused
- Using examples to clarify requirements
This difference brings in the need to have a language which can define, in an understandable format.
Here is an example of BDD using Specflow which is focused on Acceptance testing. It made it easy for anyone in the team to read and write test and with this feature it brings business users in to the test process, helping teams to explore and understand requirements:
Feature: Sign up
Sign up should be quick and friendly.
Scenario: Successful sign up
New users should get a confirmation email and be greeted
personally by the site once signed in.
Given I have chosen to sign up
When I sign up with valid details
Then I should receive a confirmation email
And I should see a personalized greeting message
Specflow will generated, based on this syntax, the corresponding test classes, where you cand write your test code.
Evolving architecture
By placing focus on the key abstractions of the domain domain and application logic at the center of the architecture, and deferring user interface, persistence and cross-cutting concerns to implementation detail, clean architecture allows to more easily evolve over time.
We want do defer the implementation details until the moment known as the last responsible moment.
The last responsible moment is a strategy to avoid making premature decisions by deferring important and difficult decisions until a point in time when the cost of not making the decision becomes greater than the cost of making the decision. Making implementation decisions too early can be a huge risk on some projects, while making the decisions too late can lead to other potential risks and technical debt as well.
Evolutionary architecture practices are about creating architecture that allows us to more easily defer decisions until the moment where we minimize the risk due to making the decision too early, but not waiting too long either. Focusing on the domain early allows us to create better design decisions instead of investing heavily in the implementation details.
Clean architecture makes it easier to defer implementation decisions or replace existing implementations, than an architecture build around an specific implementation. Evolutionary architectures embrace uncertainty, embraces change and reduces risk because of changing requirements.
DesignPatterns
clean architecture clean code
05.11.2018
Acasa