Eric Evans first published a book about Domain Driven Design in 2003 where he first described this architecture model in detail.
DDD provides principles and patterns to solve difficult software an business problems. DDD provides a clean representation of the problem in code that we can easily understand and verify through tests.
One of the main goals of DDD is to encourage better interaction with domain experts. These are the people who know best the business or process, which could be the developer, the client, or whoever is interested in knowing the problem domain. It's goal is to establish a common language between the stakeholders of an application.
There might be multiple subdomains, the idea is to focus on one domain at a time.
many applications try to do too many things at once, then adding additional behavior gets more and more difficult and expensive. With DDD you'll divide and conquer, by separating the problem into separate subdomains, each problem can be tackled independently, making the problem much easier to solve.
DDD applies separation of concerns to help you focus on the domain and not on details like how to persist data into a table, this become implementation details that you can handle separately.
The benefits of DDD are multiple, it provides a more flexible architecture, it models the customer's vision/perspective of the problem, it leads to well-organized and easily tested code.
Even when you don't use full DDD in your project, there are many patterns and practices that you can use by yourself to benefit your application.
DDD makes sense when there is complexity in the problem, for example it does not make sense to implement DD for simple CRUD data-driven applications. It should also be accepted by the team in order to be able to apply DDD.
DDD encourages the use of a ubiquitous language for clear and concise communication, to come up with terms that will be used when discussing a particular subdomain. There should be no confusion and misunderstandings about the terminology used by various members of the team.
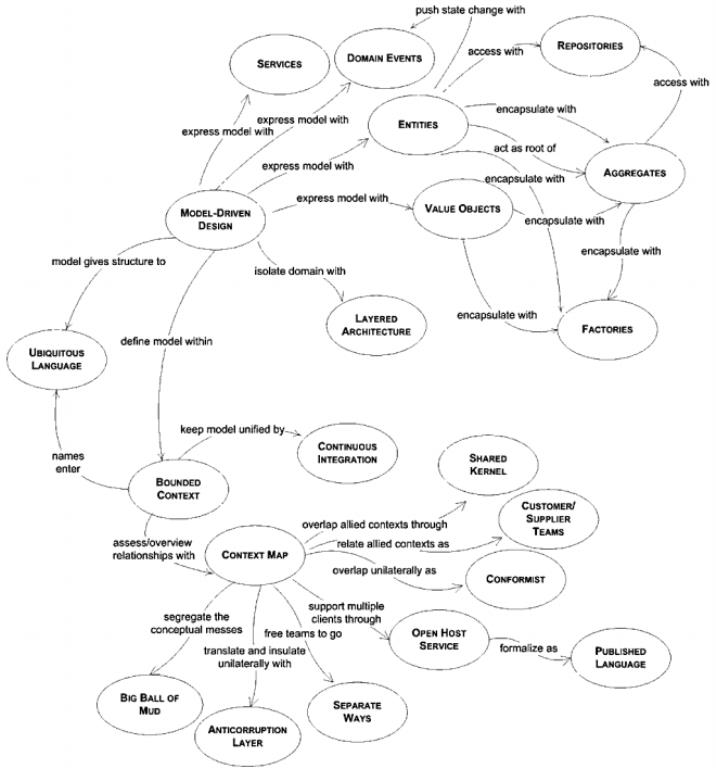
Modeling Problems in software
It is a good idea to speak with a domain expert about the system's requirement before diving in to code a solution. An overall understanding of the client's business is critical in domain driven design.
Determining what the applications needs to solve, and what it's outside of it's scope is necessary. I's also important that this is well understood and communicated among people involved in the project.
As software developers, we fail in two ways:
-we build the thing wrong
-we build the wrong thing
Bounded context
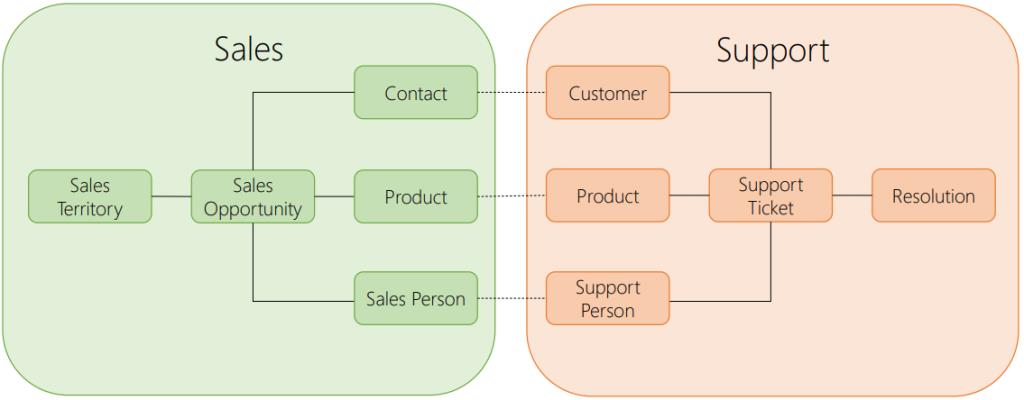
When defining a model, it's important to identify its bounded context, meaning where is a specific model valid. There should be boundaries around your model because concepts that makes sense in one part of the application may not make sense in another.
If we try to use exactly the same model in different parts of the application, may cause inconsistent behavior in our system. It can also lead to security issues when exposing to much information when sharing sensitive information between contexts.
There are parts of the application which are common to several bounded contexts. These are cross cutting concerns which are shared between contexts. In DD this is referred as a Shared Kernel which can be created as a separate component. The shared kernel shall not be changed without collaboration.
A bounded context does not mean necessary a separate application, multiple bounded contexts can be created in the same solution. The process of identifying bounded contexts and their relationships to one another is named Context Mapping.
Ubiquitous language
Using an single, shared ubiquitous language helps avoid unnecessary confusion and translation within the team building the software, including developers and business people which are driving what the software should do. This language should be used throughout a bounded context.
Elements of a Domain Model
DDD puts the main focus on the Domain, where the focus is on the behavior not on classes and properties. This is a new way of thinking instead of just thinking in classes and objects.
Entities are the key types in the system, but not every key type needs to be an Entity, for example, we could have also value objects. Services are use to put logic that doesn't logically belong in any of the entities or value objects. Entities alongside Entity Framework can be used to map them to a database for persistence, which has it's own DB context. Despite an apparent similarity of entities as key elements, Entity Framework is very different from the concept of a bounded context. The purpose of EF's DbContext is purely for mapping Entities to Databases. This might confuse a lot of developers with Entity Framework which are switching to DDD.
Focus on the domain
Focusing on the domain will help you avoid the complications and distractions that come from thinking outside of the domain or subdomain that you're working on. Eric Evans pointed out in his book:
The domain layer is responisble for representing concepts of the business, information about the business situation, and business rules. State that reflects the business situation is controlled and used here, even though the technical details of storing it are delegated to the infrastructure. This layer is the heart of business software.
Anemic vs Rich Domain Models
In a typical 3-layer database driven app, we were used to focusing on properties, or attributes of classes.
Our application became all about editing property values and the state of our objects, which is referred to an anemic domain model. Anemic domain model is represented by a collection of classes with some getters and setters, which might be fine for simple CRUD operations. However, when we are modelling a domain, we need to focus on the behaviors of that domain, not simply about changing the state of objects. DDD models are therefore named rich domain models. Rich domain models represent the behaviors and business logic of your domain.
Entities in DDD
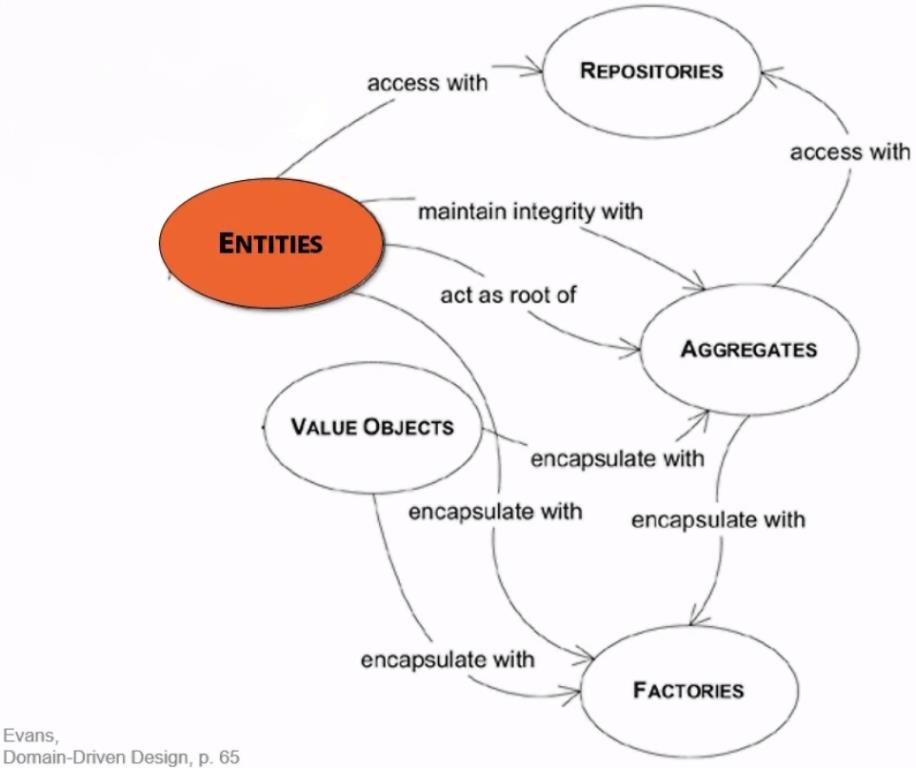
Entities are identified by an identity key and are usually integral to our software. Typically they are identified by an unique id field.
An entity represents a mutable class with an identity(not tied to it's property values) used for tracking and persistence.
DDD recommends using one way or unidirectional relationships between entities, when possible.
Value objects play an equally important role in DDD as entity objects do. Value objects measures, quantifies, or describes a thing in the domain. Value objects are immutable, compared using all values and the identity is based on composition of values. It is recommended to use value objects instead of entities wherever possible. Even when a domain concept must be modeled as an Entity, the Entity's design should be biased toward serving as a value container rather than a child Entity container.
Value objects are a really good place to put methods and logic, a better place than entities.
Methods of the entity should contain high level things that read like a use case level of communication, rather than the little details.
A value object is an immutable type whose state cannot be changed once the object has been instantiated, and whos identity is dependent on the combination of its values.
Domain Services
Services in DDD contain important operations that don't belong to a particular Entity or value Object. Good domain services are not part of an existing Entity or value Object. Services have an interface defined in terms of other domain model elements, and are stateless, but may have side effects.
Services may be used in different layers, UI layer, application layer or infrastructure layer.
Aggregates
One way to eliminate complexity in our programs is to eliminate the use of bidirectional relations you have. Another way is the use of aggregates and aggregate roots, which consist of one or more entities andvalue objects that change together. Any aggregate must have an aggregate root, which is the parent object of all members of the Aggregate, and it's possible to have an aggregate that consists of just one object.
Data changes to the Aggregate should follow the ACID principles(Atomic, Consistent, Isolated, and Durable).
An aggregate is a cluster of associated objects that we treat as a unit for the purpose of data changes.
Eric Evans, Domain-Driven Design
Aggregates serve as boundaries between logical groupings within our application. We enforce this boundaries by prohibiting direct references to objects within an aggregate that aren't the root of the Aggregate.
In the following example, the aggregate root is the Customer whereas the Address is not a root. The only way to get to the Address in this Aggregate is through the Customer:
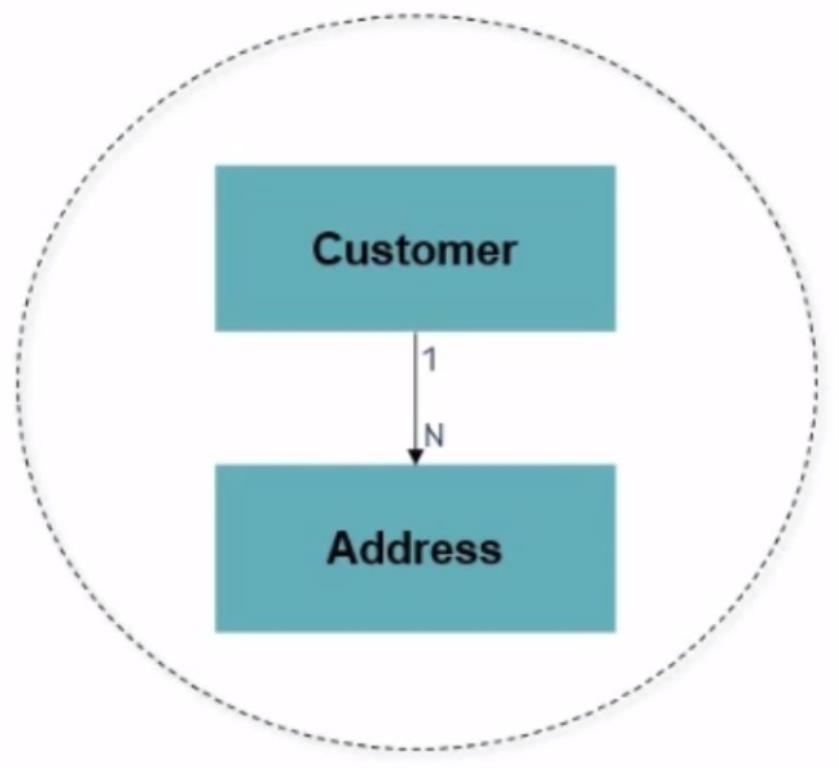
Since the customer is the root of the aggregate, it can be referenced from other aggregates.
For an object to be a good candidate for being an Aggregate Root, it should be the case that deleting that object should also delete the other objects within the Aggregate. It is recommended that the aggregate root has only foreign key relations instead of object references to the related concepts. This way, we ensure that creating and changing an aggregate root has a minimal impact on our system when we persist the appointment.
Modeling the domain is a continuous process, the domain including aggregates might not be perfect from the beginning. Your understanding about a domain will evolve and you may want to do some refactoring to improve the design.
Aggregates should be designed as persistent ignorant classes, so they are totally unaware of how they are persisted and all of the persistence logic happens in a repository.
Repositories
The repository pattern seems to be the most popular pattern used outside of Domain Driven Design. Repositories are used to simplify data access and enforce separation of concerns.
You can use repositories to manage the life cycle of your persistent objects without the objects having to know anything about their persistence.
These objects are called persistence ignorant.
The client should focus on the model while delegating all of the object storage and access to the repositories.
Repository can be treated as if they are a collection of in-memory objects.
The calling code doesn't care how the repository performs those actions, so in the repository you might have code that responds to a retrieve method, goes out to a database and gets data, or it might get data that is already cached, or even a text file.
The repositories need to have a well known interface, which is the entry point for all code which interacts with the repository.
Repositories enable testability by reducing tight coupling to external resources like database, which normally would make unit testing difficult.Using repository interfaces its easier to write tests by mocking the repository interface.
Also maintainability is increased by having repositories separate from client code and domain logic. This way we can add improvement of data access, add caching etc. without the client being aware of such optimizations.
When designing a collection of repositories, you could design a base class repository which contains a set of generic methods for all repositories, like add and remove.
Repositories should be created only for aggregate roots that require direct access. This might be different for repositories which are not part of DDD. They provide a common abstraction for persistence, promote separation of concerns, communicates design decisions through a clear interface.
Client code can be ignorant of repository implementation but developers using it cannot. This is because of some performance problems when the repository is not used correctly, like fetching more data as required, inappropriate use of eager or lazy loading etc.
Compared to Factories, Repositories are used to find and update existing objects, whereas Factories are used to only create new objects.
A Repository can use a factory to create its objects.
Lastly, Repositories should follow the ACID rules(Atomic, Consistent, Isolated, and Durable)
Atomic - Either the entire transaction occurs or none of it does
Consistent - The constraints on the data are applied
Isolated - If two different aggregates are being committed at the same time, they don't conflict
Durable - If one transaction succeeded, it can be reconstructed later
Domain events
Domain events provide a way to describe important activities or state changes that occur in the system.
Domain events are encapsulated as objects, which are used to communicate between different components in a loosly coupled manner.
The objects that are raising the events don't need to worry about the behavior that needs to occur when the event happens. Likewise, the event handling objects don't need to know where the event came from.
In DDD events are first class members of the domain model, and should be part of the ubiquitos language.
An event is a message, a record that something occured in the past which may be of interest to other parts of our applications.
Domain events are immutable, they record something that happens in the past. Domain events have it's own class, typically include the time when they happened, capture event-specific details, are initialized in the constructor, and have no behavior or side effects.
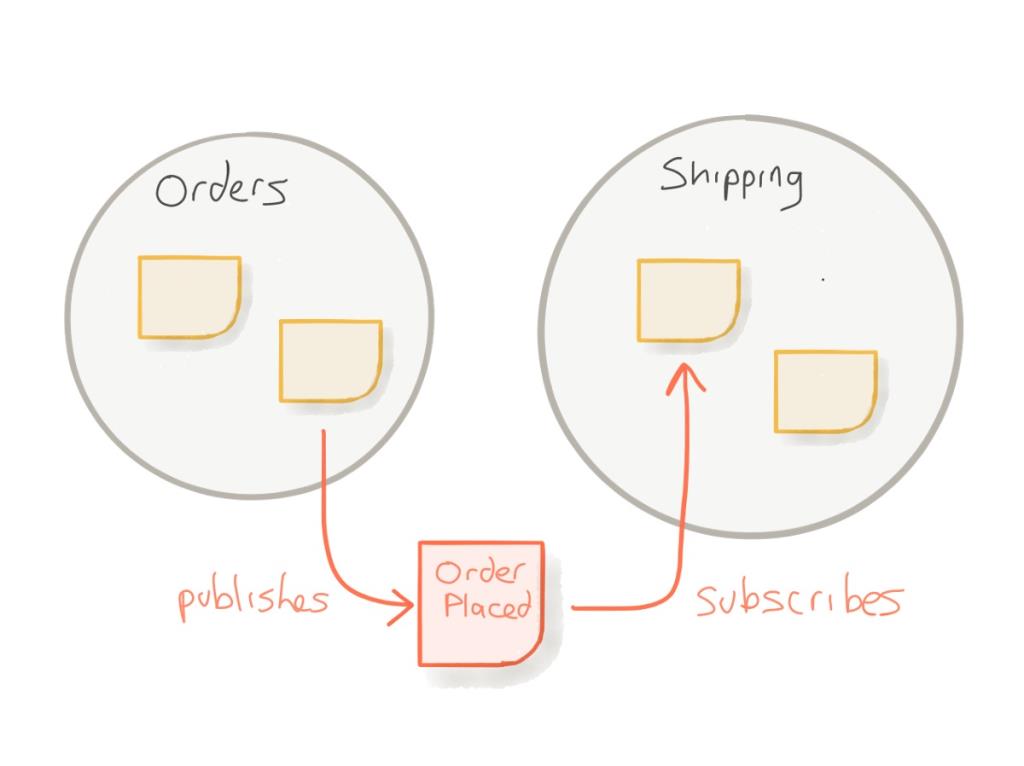
In this image, the "Orders" and "Shipping" component communicate through an "Order Placed" event, which can be exchanged through different methods, by following the publisher/subscriber pattern. One common way to communicate would be through message queues, or even service bus'es.
Message queues are a tool for storing ant retrieving messages, often used by applications to communicate with one another in a disconnected fashion. Service Bus is a software responsible for managing how messages are routed between numerous applications and services.
Anti-corruption Layers
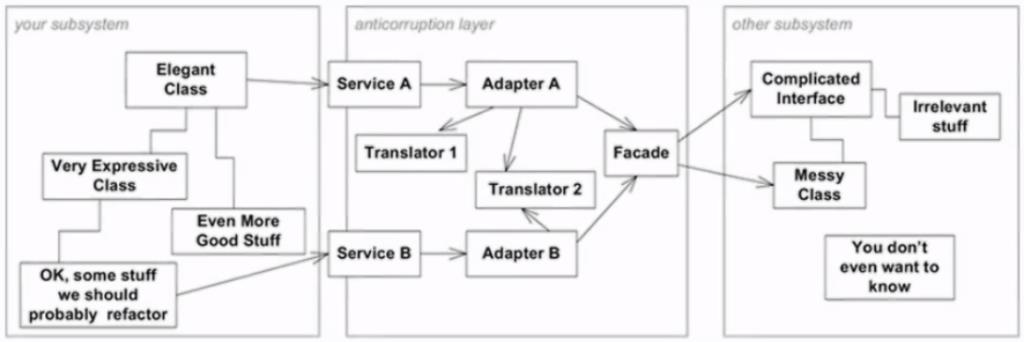
Anti-corruption layers helps to prevent corruption in your domain model. When your system needs to communicate with other systems, like legacy systems or other bounded contexts, you may need a system that translates to and from other models. This is the job of an Anti-Corruption layer.
This layer can also act as a facade or adapter for our current system. It's meaning is to simplify the way you communicate with other systems, ensure that their domain decisions does not bleed into your design, and ensure the necessary translations.
Considering the UI When Designing the Domain
The UI has an important impact of how you design the domain model, even if the main focus should be on the domain model. Thinking about the UI in the early stages of planning and revisiting it while modelling the domain is important. making some early sketches about the UI may affect the design of the domain model.The UI should not totally drive how your model will look like, but you shouldn't ignore it either.
When Should You Apply DDD
DDD is well-suited to large applications with significant business (not just technical) complexity. The application should require the knowledge of domain experts. There should be significant behavior in the domain model itself, representing business rules and interactions beyond simply storing and retrieving the current state of various records from data stores.
When Shouldn’t You Apply DDD
DDD involves investments in modeling, architecture, and communication that may not be warranted for smaller applications or applications that are essentially just CRUD (create/read/update/delete). If you choose to approach your application following DDD, but find that your domain has an anemic model with no behavior, you may need to rethink your approach. Either your application may not need DDD, or you may need assistance refactoring your application to encapsulate business logic in the domain model, rather than in your database or user interface.
A hybrid approach would be to only use DDD for the transactional or more complex areas of the application, but not for simpler CRUD or read-only portions of the application. For instance, you needn’t have the constraints of an Aggregate if you’re querying data to display a report or to visualize data for a dashboard. It’s perfectly acceptable to have a separate, simpler read model for such requirements.
DesignPatterns
domain driven design DDD
04.12.2018
Acasa